10.1 Parameter optimization in linear and nonlinear models
Before we turn to the statistical formulation of models of encoding and decoding, we need to introduce the language of statistics into neuron modeling. In particular, we will define what is meant by convex problems, optimal solutions, linear models and generalized linear models.
When choosing a neuron model for which we want to estimate the parameters from data, we must satisfy three competing desiderata:
(i) The model must be flexible and powerful enough to fit the observed data. For example, a linear model might be easy to fit, but not powerful enough to account for the data.
(ii) The model must be tractable: we need to be able to fit the model given the modest amount of data available in a physiological recording (preferably using modest computational resources as well); moreover, the model should not be so complex that we cannot assign an intuitive functional role to the inferred parameters.
(iii) The model must respect what is already known about the underlying physiology and anatomy of the system; ideally, we should be able to interpret the model parameters and predictions not only in statistical terms (e.g., confidence intervals, significance tests) but also in biophysical terms (membrane noise, dendritic filtering, etc.). For example, with a purely statistical ‘black box’ model we might be able to make predictions and test their significance, but we will not be able to make links to the biophysics of neurons.
While in general there are many varieties of encoding models that could conceivably satisfy these three conditions, in this chapter we will mainly focus on the SRM with escape noise (Chapter 9). In a more general setting (see Chapter 11), the linear filter can be interpreted not just as local biophysical processes within the neuron, but as a summary of the whole signal processing chain from sensory inputs to the neuron under consideration. In such a general setting, the SRM may also be seen as an example of a ‘generalized linear’ model (GLM) (383; 521). In the following two subsections, we review linear and generalized linear models from the point of view of neuronal dynamics: how is a stimulus encoded by the neuron?
| A | B |
|---|---|
|
 |
10.1.1 Linear Models
Let us suppose that an experimentalist injects, with a first electrode, a time-dependent current in an interval while recording with a second electrode the membrane voltage . The maximal amplitude of the input current has been chosen small enough for the neuron to stay in the subthreshold regime. We may therefore assume that the voltage is well described by our linear model
| (10.1) |
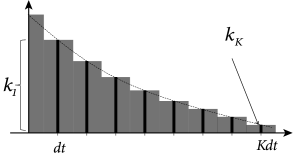
c.f. Section 1.3.5. In order to determine the filter that describes the linear properties of the experimental neuron, we discretize time in steps of and denote the voltage measurement and injected current at time by and , respectively. Here the time subscript is an integer time step counter. We set where and introduce a vector
| (10.2) |
which describes the time course in discrete time; cf. Fig. 10.1A. Similarly, the input current during the last time steps is given by the vector.
| (10.3) |
The discrete-time version of the integral equation (10.1) is then a simple scalar product
| (10.4) |
Note that is the vector of parameters that need to be estimated. In the language of statistics, Eq. 10.4 is a linear model because the observable is linear in the parameters. Moreover, is a continuous variable so that the problem of estimating the parameters falls in the class of linear regression problems. More generally, regression problems refer to the prediction or modeling of continuous variables whereas classification problems refer to the modeling or prediction of discrete variables.
In order to find a good choice of parameters , we compare the prediction of the model equation (10.4) with the experimental measurement . In a least-square error approach, the components of the vector will be chosen such that the squared difference between model voltage and experimental voltage
| (10.5) |
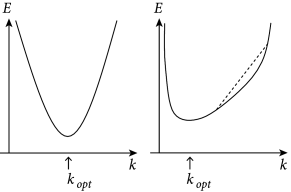
is minimal. An important insight is the following. For any model that is linear in the parameters, the function in Eq. (10.5) is quadratic and convex in the parameters of the model. Therefore,
(i) the function has no non-global local minima as a function of the parameter vector (in fact, the set of minimizers of forms a linear subspace in this case, and simple conditions are available to verify that has a single global minimum, as discussed below);
(ii) the minimum can be found either numerically by gradient descent or analytically by matrix inversion.
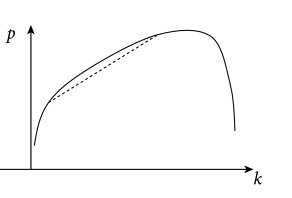
While the explicit solution is only possible for linear models, the numerical gradient descent is possible for all kinds of error functions and yields a unique solution if the error has a unique minimum. In particular, for all error functions which are convex, gradient descent converges to the optimal solution (Fig. 10.2) – and this is what we will exploit in Section 10.2.
| A | B |
|---|---|
|
 |
Example: Analytical solution
For the analytical solution of the least-square optimization problem, defined by Eqs. (10.4) and (10.5), it is convenient to collect all time points , into a single vector which describes the membrane voltage of the model. Similarly, the observed voltage in the experiment is summarized by the vector . Furthermore, let us align the observed input vectors into a matrix . More precisely, the matrix has rows consisting of the vector ; cf. Fig. 10.1B. With this notation, Eq. (10.4) can be written as a matrix equation
| (10.6) |
where is a vector with all components equal to . We suppose that the value of has already been determined in an earlier experiment.
We search for the minimum of Eq. (10.5), defined by (where denotes the gradient of w.r.t. ), which gives rise a single linear equation for each components of the parameter vector , i.e., a set of linear equations. With our matrix notation, the error function is a scalar product
| (10.7) |
and the unique solution of the set of linear equations is the parameter vector
| (10.8) |
assuming the matrix is invertible. (If this matrix is non-invertible, then a unique minimum does not exist.) The subscript highlights that the parameter has been determined by least-square optimization.
10.1.2 Generalized Linear Models
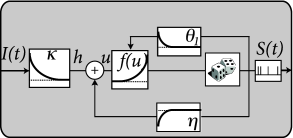
The above linearity arguments work not only in the subthreshold regime, but can be extended to the case of spiking neurons. In the deterministic formulation of the Spike Response Model, the membrane voltage is given
| (10.9) |
where is the spike train of the neuron; cf. Eq. (1.22) in Ch. 1 or (9.1) in Ch. 9. Similarly to the passive membrane, the input current enters linearly with a membrane filter . Similarly, past output spikes enter linearly with a ‘refractory kernel’ or ’adaptation filter’ . Therefore, spike history effects are treated in the SRM as linear contributions to the membrane potential. The time course of the spike history filter can therefore be estimated analogously to that of .
Regarding the subthreshold voltage, we can generalize Eqs. (10.2) - (10.4). Suppose that the spike history filter extends over a maximum of time steps. Then we can introduce a new parameter vector
| (10.10) |
which includes both the membrane filter and the spike history filter . The spike train in the last time steps is represented by the spike count sequence , where , and included into the ‘input’ vector
| (10.11) |
The discrete-time version of the voltage equation in the SRM is then again a simple scalar product
| (10.12) |
Thus, the membrane voltage during the interspike intervals is a linear regression problem that can be solved as before by minimizing the mean square error.
Spiking itself, however, is a nonlinear process. In the SRM with escape rate, the firing intensity is
| (10.13) |
We have assumed that the firing threshold is constant, but this is no limitation since, in terms of spiking, any dynamic threshold can be included into the spike-history filter .
We emphasize that the firing intensity in Eq. (10.13) is a nonlinear function of the parameters and which we need to estimate. Nevertheless, rapid parameter estimation is still possible if the function has properties that we will identify in Section 10.2. The reason is that in each time step firing is stochastic with an instantaneous firing intensity that only depends on the momentary value of the membrane potential – where the membrane potential can be written as a linear function of the parameters. This insight leads to the notion of Generalized Linear Models (GLM). For a SRM with exponential escape noise the likelihood of a spike train
| (10.14) |
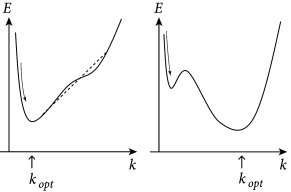
which we have already defined in Chapter 9, Eq. (9.10), is a log-concave function of the parameters (383); i.e., the loglikelihood is a concave function. We will discuss this result in the next section as it is the fundamental reason why parameter optimization for the SRM is computationally efficient (Fig. 10.3).
GLMs are fundamental tools in statistics for which a great deal of theory and computational methods are available. In the following we exploit the elegant mathematical properties of GLMs.
| A | B |
|---|---|
|
 |