19.2 Models of Hebbian learning
Before we turn to spike-based learning rules, we first review the basic concepts of correlation-based learning in a firing rate formalism. Firing rate models (cf. Ch. 15 ) have been used extensively in the field of artificial neural networks; cf. Hertz et al. ( 215 ) ; Haykin ( 209 ) for reviews.
19.2.1 A Mathematical Formulation of Hebb’s Rule
In order to find a mathematically formulated learning rule based on Hebb’s postulate we focus on a single synapse with efficacy that transmits signals from a presynaptic neuron to a postsynaptic neuron . For the time being we content ourselves with a description in terms of mean firing rates. In the following, the activity of the presynaptic neuron is denoted by and that of the postsynaptic neuron by .
There are two aspects in Hebb’s postulate that are particularly important; these are locality and joint activity . Locality means that the change of the synaptic efficacy can only depend on local variables, i.e., on information that is available at the site of the synapse, such as pre- and postsynaptic firing rate, and the actual value of the synaptic efficacy, but not on the activity of other neurons. Based on the locality of Hebbian plasticity we can write down a rather general formula for the change of the synaptic efficacy,
| (19.1) |
Here, is the rate of change of the synaptic coupling strength and is a so far undetermined function ( 465 ) . We may wonder whether there are other local variables (e.g., the input potential , cf. Ch. 15 ) that should be included as additional arguments of the function . It turns out that in standard rate models this is not necessary, since the input potential is uniquely determined by the postsynaptic firing rate, , with a monotone gain function .
The second important aspect of Hebb’s postulate is the notion of ‘joint activity’ which implies that pre- and postsynaptic neurons have to be active simultaneously for a synaptic weight change to occur. We can use this property to learn something about the function . If is sufficiently well-behaved, we can expand in a Taylor series about ,
| (19.2) |
The term containing on the right-hand side of ( 19.2.1 ) is bilinear in pre- and postsynaptic activity. This term implements the AND condition for joint activity. If the Taylor expansion had been stopped before the bilinear term, the learning rule would be called ‘non-Hebbian’, because pre- or postsynaptic activity alone induces a change of the synaptic efficacy and joint activity is irrelevant. Thus a Hebbian learning rule needs either the bilinear term with or a higher-order term (such as ) that involves the activity of both pre- and postsynaptic neurons.
Example: Hebb rules, saturation, and LTD
The simplest choice for a Hebbian learning rule within the Taylor expansion of Eq. ( 19.2.1 ) is to fix at a positive constant and to set all other terms in the Taylor expansion to zero. The result is the prototype of Hebbian learning,
| (19.3) |
We note in passing that a learning rule with is usually called anti-Hebbian because it weakens the synapse if pre- and postsynaptic neuron are active simultaneously; a behavior that is just contrary to that postulated by Hebb.
Note that, in general, the coefficient may depend on the current value of the weight . This dependence can be used to limit the growth of weights at a maximum value . The two standard choices of weight-dependence are called ’hard bound’ and ‘soft bound’, respectively. Hard bound means that is constant in the range and zero otherwise. Thus, weight growth stops abruptly if reaches the upper bound .
A soft bound for the growth of synaptic weights can be achieved if the parameter in Eq. ( 19.3 ) tends to zero as approaches its maximum value ,
| (19.4) |
with positive constants and . The typical value of the exponent is , but other choices are equally possible ( 202 ) . For , the soft-bound rule ( 19.4 ) converges to the hard-bound one.
Note that neither Hebb’s original proposal nor the simple rule ( 19.3 ) contain a possibility for a decrease of synaptic weights. However, in a system where synapses can only be strengthened, all efficacies will eventually saturate at their upper maximum value. Our formulation ( 19.2.1 ) is sufficiently general to allow for a combination of synaptic potentiation and depression. For example, if we set in ( 19.4 ) and combine it with a choice , we obtain a learning rule
| (19.5) |
where, in the absence of stimulation, synapses spontaneously decay back to zero. Many other combinations of the parameters in Eq. ( 19.2.1 ) exist. They all give rise to valid Hebbian learning rules that exhibit both potentiation and depression; cf. Table 19.1 .
| ON | ON | + | + | + | + | + |
| ON | OFF | 0 | 0 | |||
| OFF | ON | 0 | 0 | |||
| OFF | OFF | 0 | 0 | 0 | + |
Example: Covariance rule
Sejnowski ( 467 ) has suggested a learning rule of the form
| (19.6) |
called covariance rule. This rule is based on the idea that the rates and fluctuate around mean values that are taken as running averages over the recent firing history. To allow a mapping of the covariance rule to the general framework of Eq. ( 19.2.1 ), the mean firing rates and have to be constant in time.
Example: Oja’s rule
All of the above learning rules had . Let us now consider a nonzero quadratic term . We take and set all other parameters to zero. The learning rule
| (19.7) |
is called Oja’s rule ( 369 ) . Under some general conditions Oja’s rule converges asymptotically to synaptic weights that are normalized to while keeping the essential Hebbian properties of the standard rule of Eq. ( 19.3 ); see Exercises. We note that normalization of implies competition between the synapses that make connections to the same postsynaptic neuron, i.e., if some weights grow, others must decrease.
Example: Bienenstock-Cooper-Munro rule
Higher-order terms in the expansion on the right-hand side of Eq. ( 19.2.1 ) lead to more intricate plasticity schemes. Let us consider
| (19.8) |
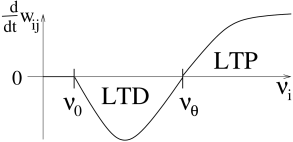
with a nonlinear function and a reference rate . If we take to be a function of the average output rate , then we obtain the so-called Bienenstock-Cooper-Munro (BCM) rule ( 58 ) .
The basic structure of the function is sketched in Fig. 19.5 . If presynaptic activity is combined with moderate levels of postsynaptic excitation, the efficacy of synapses activated by presynaptic input is decreased . Weights are increased only if the level of postsynaptic activity exceeds a threshold, . The change of weights is restricted to those synapses which are activated by presynaptic input. A common choice for the function is
| (19.9) |
which can be mapped to the Taylor expansion of Eq. ( 19.2.1 ) with and .
For stationary input, it can be shown that the postsynaptic rate under the BCM-rule ( 19.9 ) has a fixed point at which is unstable (see Exercises). In order to avoid that the postsynaptic firing rate blows up or decays to zero, it is therefore necessary to turn into an adaptive variable which depends on the average rate . The BCM rule leads to input selectivity (see Exercises) and has been successfully used to describe the development of receptive fields ( 58 ) .
19.2.2 Pair-based Models of STDP
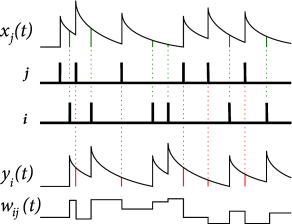
We now switch from rate-based models of synaptic plasticity to a description with spikes. Suppose a presynaptic spike occurs at time and a postsynaptic one at time . Most models of STDP interpret the biological evidence in terms of a pair-based update rule, i.e. the change in weight of a synapse depends on the temporal difference ; cf. Fig. 19.4 F. In the simplest model, the updates are
| (19.10) |
where describes the dependence of the update on the current weight of the synapse. Usually is positive and is negative. The update of synaptic weights happens immediately after each presynaptic spike (at time ) and each postsynaptic spike (at time ). A pair-based model is fully specified by defining: (i) the weight-dependence of the amplitude parameter ; (ii) which pairs are taken into consideration to perform an update. A simple choice is to take all pairs into account. An alternative is to consider for each postsynaptic spike only the nearest presynaptic spike or vice versa. Note that spikes that are far apart hardly contribute because of the exponentially fast decay of the update amplitude with the interval . Instead of an exponential decay ( 489 ) , some other arbitrary time-dependence, described by a learning window for LTP and for LTD is also possible ( 176; 256 ) .
If we introduce and for the spike trains of pre- and postsynaptic neurons, respectively, then we can write the update rule in the form ( 262 )
| (19.11) |
where denotes the time course of the learning window while and are non-Hebbian contributions, analogous to the parameters and in the rate-based model of Eq. 19.2.1 . In the standard pair-based STDP rule, we have and ; cf. Eq. ( 19.10 ).
Example: Implementation by local variables
The pair-based STDP rule of Eq. ( 19.10 ) can be implemented with two local variables, i.e. one for a low-pass filtered version of the presynaptic spike train and one for the postsynaptic spikes. Suppose that each presynaptic spike at synapse leaves a trace , i.e. its update rule is
| (19.12) |
where if the firing time of the presynaptic neuron. In other words, the variable is increased by an amount of one at the moment of a presynaptic spike and decreases exponentially with time constant afterward. Similarly, each postsynaptic spike leaves a trace
| (19.13) |
The traces and play an important role during the weight update. At the moment of a presynaptic spike, a decrease of the weight is induced proportional to the value of the postsynaptic trace . Analogously, potentiation of the weight occurs at the moment of a postsynaptic spike proportional to the trace left by a previous presynaptic spike,
| (19.14) |
The traces and correspond here to the factors in Eq. ( 19.10 ). For the weight-dependence of the factors and , one can use either hard bounds or soft bounds; cf. Eq. ( 19.4 ).
19.2.3 Generalized STDP models
There is considerable evidence that the pair-based STDP rule discussed above cannot give a full account of experimental results with STDP protocols. Specifically, they reproduce neither the dependence of plasticity on the repetition frequency of pairs of spikes in an experimental protocol, nor the results of triplet and quadruplet experiments.
STDP experiments are usually carried out with about pairs of spikes. The temporal distance of the spikes in the pair is of the order of a few to tens of milliseconds, whereas the temporal distance between the pairs is of the order of hundreds of milliseconds to seconds. In the case of a potentiation protocol (i.e. pre-before-post), standard pair-based STDP models predict that if the repetition frequency is increased, the strength of the depressing interaction (i.e. post-before-pre) becomes greater, leading to less net potentiation. However, experiments show that increasing the repetition frequency leads to an increase in potentiation ( 483; 468 ) . Other experimentalists have employed multiple-spike protocols, such as repeated presentations of symmetric triplets of the form pre-post-pre and post-pre-post ( 53; 160; 542; 159 ) . Standard pair-based models predict that the two sequences should give the same results, as they each contain one pre-post pair and one post-pre pair. Experimentally, this is not the case.
Here we review two examples of simple models which account for these experimental findings ( 394; 99 ) , but there are other models which also reproduce frequency dependence, e.g., ( 469 ) .
Triplet model
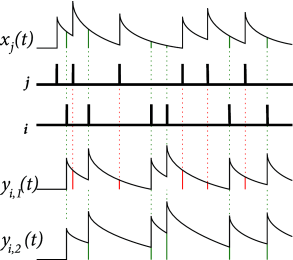
One simple approach to modeling STDP which addresses the issues of frequency dependence is the triplet rule developed by Pfister and Gerstner ( 394 ) . In this model, LTP is based on sets of three spikes (one presynaptic and two postsynaptic). The triplet rule can be implemented with local variables as follows. Similarly to pair-based rules, each spike from presynaptic neuron contributes to a trace at the synapse:
where denotes the firing times of the presynaptic neuron. Unlike pair-based rules, each spike from postsynaptic neuron contributes to a fast trace and a slow trace at the synapse:
where , see Fig. 19.7 . The new feature of the rule is that LTP is induced by a triplet effect: the weight change is proportional to the value of the presynaptic trace evaluated at the moment of a postsynaptic spike and also to the slow postsynaptic trace remaining from previous postsynaptic spikes:
| (19.15) |
where indicates that the function is to be evaluated before it is incremented due to the postsynaptic spike at . LTD is analogous to the pair-based rule, given in 19.14 , i.e. the weight change is proportional to the value of the fast postsynaptic trace evaluated at the moment of a presynaptic spike.
| A | B |
|---|---|
|
|
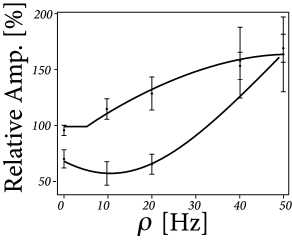
The triplet rule reproduces experimental data from visual cortical slices ( 483 ) that increasing the repetition frequency in the STDP pairing protocol increases net potentiation ( 19.8 ). It also gives a good fit to experiments based on triplet protocols in hippocampal culture ( 542 ) .
The main functional advantage of such a triplet learning rule is that it can be mapped to the BCM rule of Eqs. ( 19.8 ) and ( 19.9 ): if we assume that the pre- and postsynaptic spike trains are governed by Poisson statistics, the triplet rule exhibits depression for low postsynaptic firing rates and potentiation for high postsynaptic firing rates ( 394 ) ; see Exercises. If we further assume that the triplet term in the learning rule depends on the mean postsynaptic frequency, a sliding threshold between potentiation and depression can be defined. In this way, the learning rule matches the requirements of the BCM theory and inherits the properties of the BCM learning rule such as the input selectivity (see exercises). From the BCM properties, we can immediately conclude that the triplet model should be useful for receptive field development ( 58 ) .
Example: Plasticity model with voltage dependence
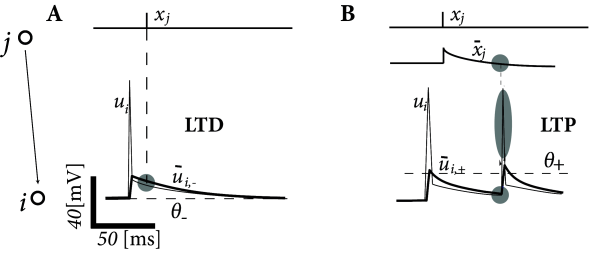
Spike timing dependence is only one of several manifestations of synaptic plasticity. Apart from spike timing, synaptic plasticity also depends on several other variables, in particular on postsynaptic voltage (Fig. 19.3 ). In this example, we present the voltage-dependent model of ( 99 ) .
The Clopath model exhibits separate additive contributions to the plasticity rule, one for LTD and another one for LTP. For the LTD part, presynaptic spike arrival at a synapse from a presynaptic neuron to a postsynaptic neuron induces depression of the synaptic weight by an amount that is proportional to the average postsynaptic depolarization . The brackets indicate rectification, i.e. any value does not lead to a change; cf. Artola et al. ( 29 ) and Fig. 19.3 . The quantity is an low-pass filtered version of the postsynaptic membrane potential with a time constant :
Introducing the presynaptic spike train , the update rule for depression is (Fig. 19.9 )
| (19.16) |
where is an amplitude parameter that depends on the mean depolarization of the postsynaptic neuron, averaged over a time scale of 1 second. A choice where is a reference value, is a simple method to avoid a run-away of the rate of the postsynaptic neuron, analogous to the sliding threshold in the BCM rule of Eq. ( 19.9 ). A comparison with the triplet rule above shows that the role of the trace (which represents a low-pass filter of the postsynaptic spike train, cf. Eq. ( 19.13 )) is taken over by the low-pass filter of the postsynaptic voltage.
For the LTP part, we assume that each presynaptic spike at the synapse increases the trace of some biophysical quantity, which decays exponentially with a time constant in the absence of presynaptic spikes; cf. Eq. ( 19.12 ). The potentiation of depends on the trace and the postsynaptic voltage via (see also Fig. 19.9 )
| (19.17) |
Here, is a constant parameter and is another low-pass filtered version of similar to but with a shorter time constant around 10ms. Thus positive weight changes can occur if the momentary voltage surpasses a threshold and, at the same time the average value is above . Note again the similarity to the triplet STDP rule. If the postsynaptic voltage is dominated by spikes, so that the Clopath model and the triple STDP rule are in fact equivalent.
The Clopath rule is summarized by the equation
| (19.18) |
combined with hard bounds .
The plasticity rule can be fitted to experimental data and can reproduce several experimental paradigms ( 483 ) that cannot be explained by pair-based STDP or other phenomenological STDP rules without voltage dependence.