19.3 Unsupervised learning
In artificial neural networks some, or even all, neurons receive input from external sources as well as from other neurons in the network. Inputs from external sources are typically described as a statistical ensemble of potential stimuli. Unsupervised learning in the field of artificial neural networks refers to changes of synaptic connections which are driven by the statistics of the input stimuli – in contrast to supervised learning or reward-based learning where the network parameters are optimized to achieve, for each stimulus, an optimal behavior. Hebbian learning rules, as introduced in the previous section, are the prime example of unsupervised learning in artificial neural networks.
In the following we always assume that there are input neurons . Their firing rates are chosen from a set of firing rate patterns with index . While one of the patterns, say pattern with is presented to the network, the firing rates of the input neurons are . In other words, the input rates form a vector where . After a time a new input pattern is randomly chosen from the set of available patterns. We call this the static pattern scenario.
19.3.1 Competitive learning
In the framework of Eq. ( 19.2.1 ), we can define a Hebbian learning rule of the form
| (19.19) |
where is a positive constant and is some reference value that may depend on the current value of . A weight change occurs only if the postsynaptic neuron is active, . The direction of the weight change depends on the sign of the expression in the rectangular brackets.
Let us suppose that the postsynaptic neuron is driven by a subgroup of highly active presynaptic neurons ( and ). Synapses from one of the highly active presynaptic neurons onto neuron are strengthened while the efficacy of other synapses that have not been activated is decreased. Firing of the postsynaptic neuron thus leads to LTP at the active pathway (‘homosynaptic LTP’) and at the same time to LTD at the inactive synapses (‘heterosynaptic LTD’); for reviews see Brown et al. ( 76 ) ; Bi and Poo ( 54 ) .
A particularly interesting case from a theoretical point of view is the choice , i.e.,
| (19.20) |
The synaptic weights thus move toward the fixed point whenever the postsynaptic neuron is active. In the stationary state, the set of weight values reflects the presynaptic firing pattern . In other words, the presynaptic firing pattern is stored in the weights.
The above learning rule is an important ingredient of competitive unsupervised learning ( 271; 200 ) . To implement competitive learning, an array of (postsynaptic) neurons receive input from the same set of presynaptic neurons which serve as the input layer. The postsynaptic neurons inhibit each other via strong lateral connections, so that, whenever a stimulus is applied at the input layer, the postsynaptic neuron compete with each other and only a single postsynaptic neuron responds. The dynamics in such competitive networks where only a single neuron ’wins’ the competition has already been discussed in Chapter 16 .
In a learning paradigm with the static pattern scenario, all postsynaptic neurons use the same learning rule ( 19.20 ), but only the active neuron (i.e., the one which ‘wins’ the competition) will effectively update its weights (all others have zero update because for ). The net result is that the weight vector of the winning neuron moves closer to the current vector of inputs . For a different input pattern the same or another postsynaptic neuron may win the competition. Therefore, different neurons specialize for different subgroups (’clusters’) of patterns and each neuron develops a weight vector which represents the center of mass of ‘its’ cluster.
Example: Developmental learning with STDP
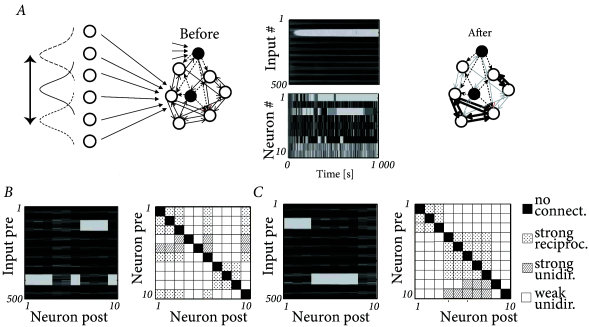
The results of simulations of the Clopath model shown in Fig. 19.10 can be interpreted as a realization of a soft form of competitive learning. Neurons form subnetworks that specialize on the same features of the input. Because of inhibition, different subnetworks specialize on different segments of the input space.
Ten excitatory neurons (with all-to-all connectivity) are linked to three inhibitory neurons. Each inhibitory neuron receives input from 8 randomly selected excitatory neurons and randomly projects back to 6 excitatory neurons ( 99 ) . In addition to the recurrent input, each excitatory and inhibitory neuron receives feedforward spike input from 500 presynaptic neurons that generate stochastic Poisson input at a rate . The input neurons can be interpreted as a sensory array. The rates of neighboring input neurons are correlated, mimicking the presence of a spatially extended object stimulating the sensory layer. Spiking rates at the sensory layer change every 100ms.
Feedforward connections and lateral connections between model pyramidal neurons are plastic whereas connections to and from inhibitory neurons are fixed. In a simulation of the model network, the excitatory neurons developed localized receptive fields, i.e., weights from neighboring inputs to the same postsynaptic neuron become either strong or weak together (Fig. 19.10 A). Similarly, lateral connections onto the same postsynaptic neuron develop strong or weak synapses, that remain, apart from fluctuations, stable thereafter (Fig. 19.10 A) leading to a structured pattern of synaptic connections (Fig. 19.10 B). While the labeling of the excitatory neurons at the beginning of the experiment was randomly assigned, we can relabel the neurons after the formation of lateral connectivity patterns so that neurons with similar receptive fields have similar indices. After reordering we can clearly distinguish that two groups of neurons have been formed, characterized by similar receptive fields and strong bidirectional connectivity within the group, and different receptive fields and no lateral connectivity between groups (Fig. 19.10 C).
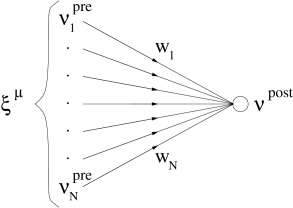
19.3.2 Learning equations for rate models
We focus on a single analog neuron that receives input from presynaptic neurons with firing rates via synapses with weights ; cf. Fig. 19.11 A. Note that we have dropped the index of the postsynaptic neuron since we focus in this section on a single output neuron. We think of the presynaptic neurons as ‘input neurons’, which, however, do not have to be sensory neurons. The input layer could, for example, may consist of neurons in the lateral geniculate nucleus (LGN) that project to neurons in the visual cortex. As before, the firing rate of the input neurons is modeled by the static pattern scenario. We will show that the statistical properties of the input control the evolution of synaptic weights. In particular, we identify the conditions under which unsupervised Hebbian learning is related to Principal Component Analysis (PCA).
In the following we analyze the evolution of synaptic weights using the simple Hebbian learning rule of Eq. ( 19.3 ). The presynaptic activity drives the postsynaptic neuron and the joint activity of pre- and postsynaptic neurons triggers changes of the synaptic weights:
| (19.21) |
Here, is a small constant called ‘learning rate’. The learning rate in the static-pattern scenario is closely linked to the correlation coefficient in the continuous-time Hebb rule introduced in Eq. ( 19.3 ). In order to highlight the relation, let us assume that each pattern is applied during an interval . For sufficiently small, we have .
| A | B |
|---|---|
|
|
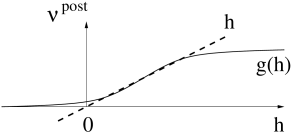
In a general rate model, the firing rate of the postsynaptic neuron is given by a nonlinear function of the total input
| (19.22) |
cf. Fig. 19.11 B and Chapter 15 . For the sake of simplicity, we restrict our discussion in the following to a linear rate model with
| (19.23) |
where we have introduced a vector notation for the weights , the presynaptic rates and the dot denotes a scalar product. Hence we can interpret the output rate as a projection of the input vector onto the weight vector.
If we combine the learning rule ( 19.21 ) with the linear rate model of Eq. ( 19.23 ) we find after the presentation of pattern
| (19.24) |
The evolution of the weight vector is thus determined by the iteration
| (19.25) |
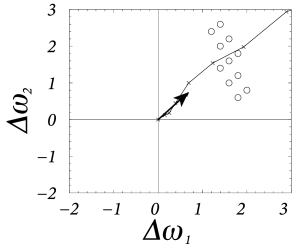
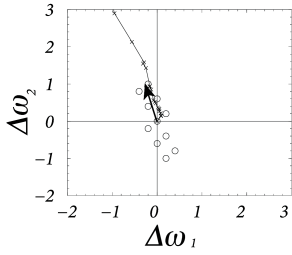
where denotes the pattern that is presented during the th time step. Eq. ( 19.25 ) is called an ‘online’ rule, because the weight update happens immediately after the presentation of each pattern. The evolution of the weight vector during the presentation of several patterns is shown in Fig. 19.12 .
| A | B |
|---|---|
|
|
If the learning rate is small, a large number of patterns has to be presented in order to induce a substantial weight change. In this case, there are two equivalent routes to proceed with the analysis. The first one is to study a version of learning where all patterns are presented before an update occurs. Thus, Eq. ( 19.25 ) is replaced by
| (19.26) |
with a new learning rate . This is called a ‘batch update’. With the batch update rule, the right hand side can be rewritten as
| (19.27) |
where we have introduced the correlation matrix
| (19.28) |
Thus, the evolution of the weights is driven by the correlations in the input.
The second, alternative, route is to stick to the online update rule, but study the expectation value of the weight vector, i.e., the weight vector averaged over the sequence of all patterns that so far have been presented to the network. From Eq. ( 19.25 ) we find
| (19.29) |
The angular brackets denote an ensemble average over the whole sequence of input patterns . The second equality is due to the fact that input patterns are chosen independently in each time step, so that the average over and can be factorized. Note that Eq. ( 19.3.2 ) for the expected weights in the online rule is equivalent to Eq. ( 19.27 ) for the weights in the batch rule.
Expression ( 19.3.2 ), or equivalently ( 19.27 ), can be written in a more compact form using matrix notation (we drop the angular brackets in the following)
| (19.30) |
where is the weight vector and is the identity matrix.
If we express the weight vector in terms of the eigenvectors of ,
| (19.31) |
we obtain an explicit expression for for any given initial condition , viz.,
| (19.32) |
Since the correlation matrix is positive semi-definite, all eigenvalues are real and positive. Therefore, the weight vector is growing exponentially, but the growth will soon be dominated by the eigenvector with the largest eigenvalue, i.e., the first principal component ,
| (19.33) |
Recall that the output of the linear neuron model ( 19.23 ) is proportional to the projection of the current input pattern on the direction . For , the output is therefore proportional to the projection on the first principal component of the input distribution. A Hebbian learning rule such as ( 19.21 ) is thus able to extract the first principal component of the input data.
From a data-processing point of view, the extraction of the first principal component of the input data set by a biologically inspired learning rule seems to be very compelling. There are, however, a few drawbacks and pitfalls when using the above simple Hebbian learning scheme. Interestingly, all three can be overcome by slight modifications in the Hebb rule.
First, the above statement about the Hebbian learning rule is limited to the expectation value of the weight vector. However, it can be shown that if the learning rate is sufficiently low, then the actual weight vector is very close to the expected one so that this is not a major limitation.
Second, while the direction of the weight vector moves in the direction of the principal component, the norm of the weight vector grows without bounds. However, variants of Hebbian learning such as the Oja learning rule ( 19.7 ) allow us to normalize the length of the weight vector without changing its direction; cf. Exercises.
Third, principal components are only meaningful if the input data is normalized, i.e., distributed around the origin. This requirement is not consistent with a rate interpretation because rates are usually positive. This problem, however, can be overcome by learning rules such as the covariance rule of Eq. ( 19.6 ) that are based on the deviation of the rates from a certain mean firing rate. Similarly, STDP rules can be designed in a way that the output rate remains normalized so that learning is sensitive only to deviations from the mean firing rate and can thus find the first principal component even if the input is not properly normalized ( 256; 489; 257 ) .
Example: Correlation matrix and Principal Component Analysis
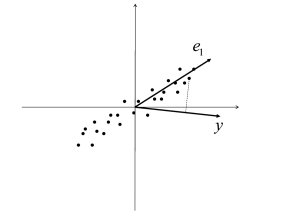
For readers not familiar with principal component analysis (PCA) we review here the basic ideas and main results. PCA is a standard technique to describe statistical properties of a set of high-dimensional data points and is performed to find the direction in which the data shows the largest variance. If we think of the input data set as of a cloud of points in a high-dimensional vector space centered around the origin, then the first principal component is the direction of the longest axis of the ellipsoid that encompasses the cloud; cf. Fig. 19.13 A. In the following, we will explain the basic idea and show that the first principal component gives the direction where the variance of the data is maximal.
Let us consider an ensemble of data points drawn from a (high-dimensional) vector space, for example . For this set of data points we define the correlation matrix as
| (19.34) |
Angular brackets denote an average over the whole set of data points. Similar to the variance of a single random variable we can also define the covariance matrix of our data set,
| (19.35) |
In the following we will assume that the coordinate system is chosen so that the center of mass of the set of data points is located at the origin, i.e., . In this case, correlation matrix and covariance matrix are identical.
The principal components of the set are defined as the eigenvectors of the covariance matrix . Note that is symmetric, i.e., . The eigenvalues of are thus real-valued and different eigenvectors are orthogonal ( 229 ) . Furthermore, is positive semi-definite since
| (19.36) |
for any vector . Therefore, all eigenvalues of are non-negative.
We can sort the eigenvectors according to the size of the corresponding eigenvalues . The eigenvector with the largest eigenvalue is called the first principal component.
The first principal component points in the direction where the variance of the data is maximal. To see this we calculate the variance of the projection of onto an arbitrary direction (Fig. 19.13 B) that we write as with so that . The variance along is
| (19.37) |
The right-hand side is maximal under the constraint if and for , that is, if .
| A | B |
|---|---|

|
|
19.3.3 Learning equations for STDP models (*)
The evolution of synaptic weights in the pair-based STDP model of Eq. ( 19.10 ) can be assessed by assuming that pre- and postsynaptic spike trains can be described by Poisson processes. For the postsynaptic neuron, we take the linear Poisson model in which the output spike train is generated by an inhomogeneous Poisson process with rate
| (19.38) |
with scaling factor , threshold and membrane potential , where denotes the time course of an excitatory postsynaptic potential generated by a presynaptic spike arrival. The notation denotes a piecewise linear function: for and zero otherwise. In the following we assume that the argument of our piecewise linear function is positive so that we can suppress the square brackets.
For the sake of simplicity, we assume that all input spike trains are Poisson processes with a constant firing rate . In this case the expected firing rate of the postsynaptic neuron is simply:
| (19.39) |
where is the total area under an excitatory postsynaptic potential. The conditional rate of firing of the postsynaptic neuron, given an input spike at time is given by
| (19.40) |
Since the conditional rate is different from the expected rate, the postsynaptic spike train is correlated with the presynaptic spike trains . The correlations can be calculated to be
| (19.41) |
Similar to the expected weight evolution for rate models in Section 19.3.2 , we now study the expected weight evolution in the spiking model with the pair-based plasticity rule of Eq. 19.10 . The result is ( 256 )
| (19.42) |
The first term is reminiscent of rate-based Hebbian learning, Eq. ( 19.3 ), with a coefficient proportional to the integral under the learning window. The last term is due to pre-before-post spike timings that are absent in a pure rate model. Hence, despite the fact that we started off with a pair-based STDP rule, the synaptic dynamics contains a term of the form that is linear in the presynaptic firing rate ( 256; 257 ) .
Example: Stabilization of postsynaptic firing rate
If spike arrival rates at all synapses are identical, we expect a solution of the learning equation to exist where all weights are identical, . For simplicity we drop the averaging signs. Eq. ( 19.42 ) then becomes
| (19.43) |
Moreover, we can use Eq. ( 19.39 ) to express the postsynaptic firing rate in terms of the input rate .
| (19.44) |
If the weight increases, the postsynaptic firing rate does as well. We now ask whether the postsynaptic firing has a fixed point .
The fixed point analysis can be performed for a broad class of STDP models. However, for the sake of simplicity we focus on the model with hard bounds in the range where . We introduce a constant . If the integral of the learning window is negative, then and LTD dominates over LTP. In this case, a fixed point exists at
| (19.45) |
where denotes the contribution of the spike-spike correlations. The mean firing rate of the neuron is, under rather general conditions, stabilized at the fixed point ( 257 ) . Hence STDP can lead to a control of the postsynaptic firing rate ( 256; 489; 257 ) . We emphasize that the existence of a fixed point and its stability does not crucially depend on the presence of soft or hard bounds on the weights. Since for constant input rates , we have , stabilization of the output rate automatically implies normalization of the summed weights.